Your AI Pentest Agent Has No Rules. Until Now.
The first out-of-band reference monitor for autonomous security testing agents. Enforce Rules of Engagement with cryptographic guarantees. Not prompts.
The first out-of-band reference monitor for autonomous security testing agents. Enforce Rules of Engagement with cryptographic guarantees. Not prompts.
Today's AI pentest agents run with system prompts that say "stay in scope." But system prompts are suggestions, not guardrails. The research is clear:
ROE Gate sits between the agent and every tool it uses. Every action is serialized, evaluated against your ROE policy, and cryptographically signed before execution. The agent never touches the signing keys.
Every tool call gets converted to a structured ActionIntent. Tool-agnostic, machine-readable, auditable. 24 action categories cover every pentest technique.
Human-readable YAML that defines scope, allowed actions, denied actions, schedules, data handling, and emergency procedures. Your contract, as code.
Eight evaluation checks in strict priority order: schedule, scope (IP/domain/service), hard-deny, approval gates, action constraints, hard-allow, and fallback. No ambiguity.
A separate LLM instance with no agent context evaluates edge cases. It sees only the action and the policy. Immune to prompt injection from the agent. Supports any judge provider: Anthropic, OpenAI, Google Gemini, Ollama, AWS Bedrock, local Transformers, llama.cpp, and any OpenAI-compatible endpoint.
Approved actions get HMAC-SHA256 tokens with 30-second TTL, single-use enforcement, and ROE-hash binding. The agent cannot forge, replay, or reuse tokens.
Tools only run after 6-step token verification: signature, expiration, replay check, ROE hash, action match, and tool whitelist. No valid token = no execution.
Visual drag-and-drop ROE specification builder. Define scope, actions, constraints, and schedule through a beautiful web interface. Export valid YAML instantly.
The agent calls an MCP tool (e.g., roe_nmap_scan). The tool call is serialized into a structured ActionIntent and sent to the Gate Service over HTTP.
The deterministic Rule Engine checks scope, schedule, and policy. Edge cases go to the isolated Judge LLM. Hard denials are instant. No LLM call needed.
If approved, the Gate signs an HMAC-SHA256 token (30s TTL, single-use). The Tool Executor verifies the token before running the command. No token = no execution.
Every evaluation, every decision, every token — live in your browser. Filter by verdict, search by tool or target, drill into rule engine and judge reasoning, generate compliance reports, and manage ROE specs. All from a single pane of glass.
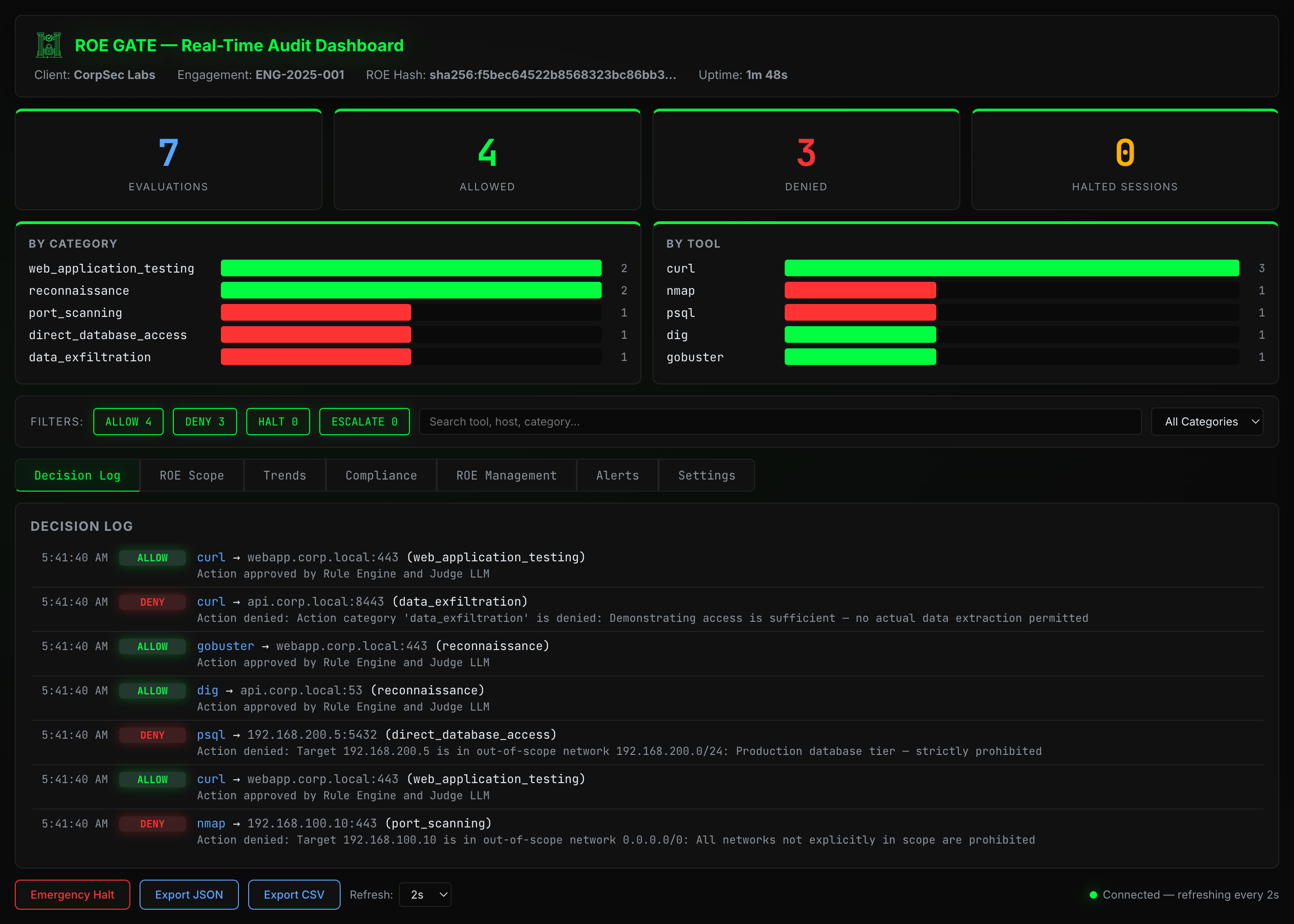
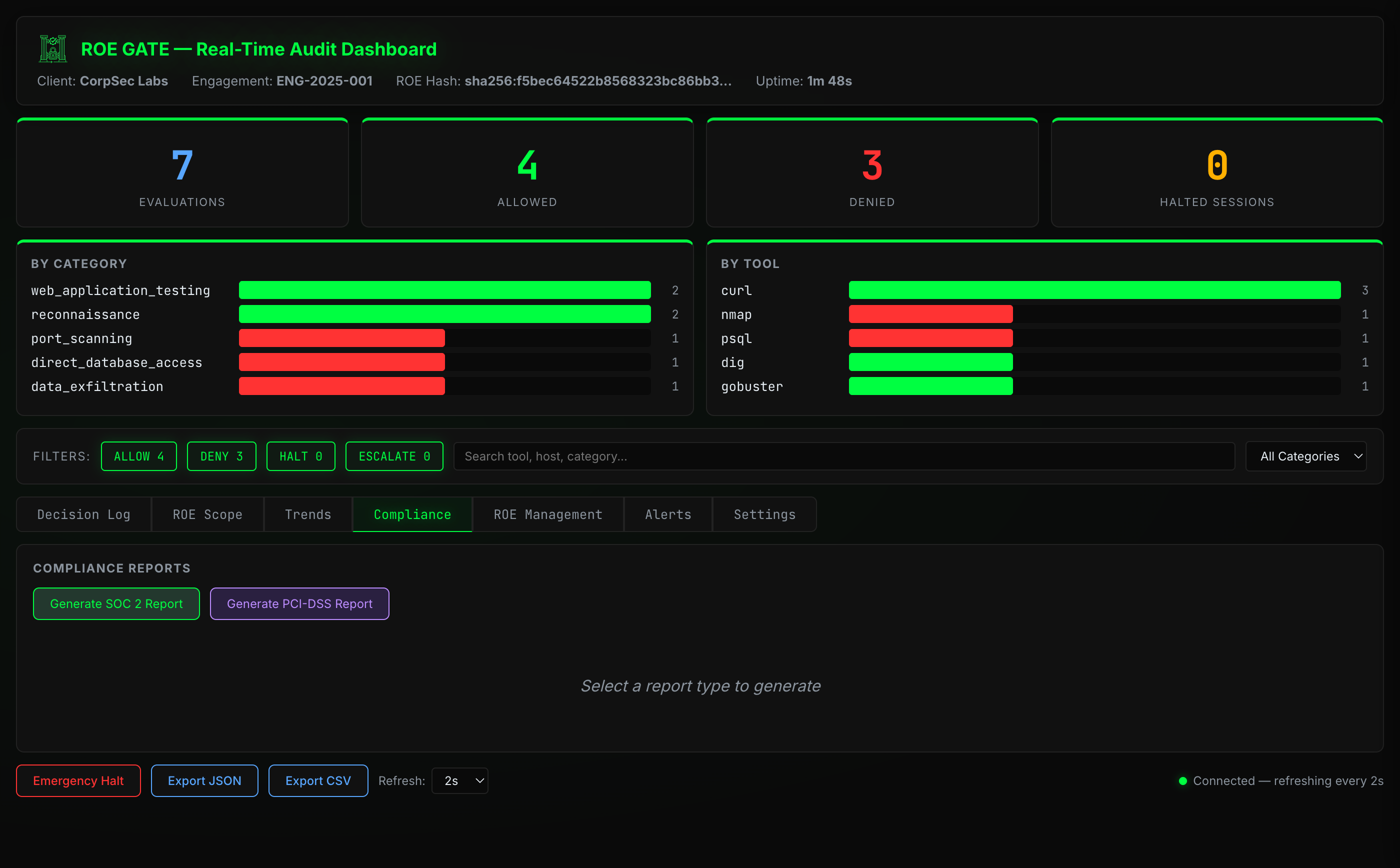
Compliance — SOC 2 Type II report with evidence
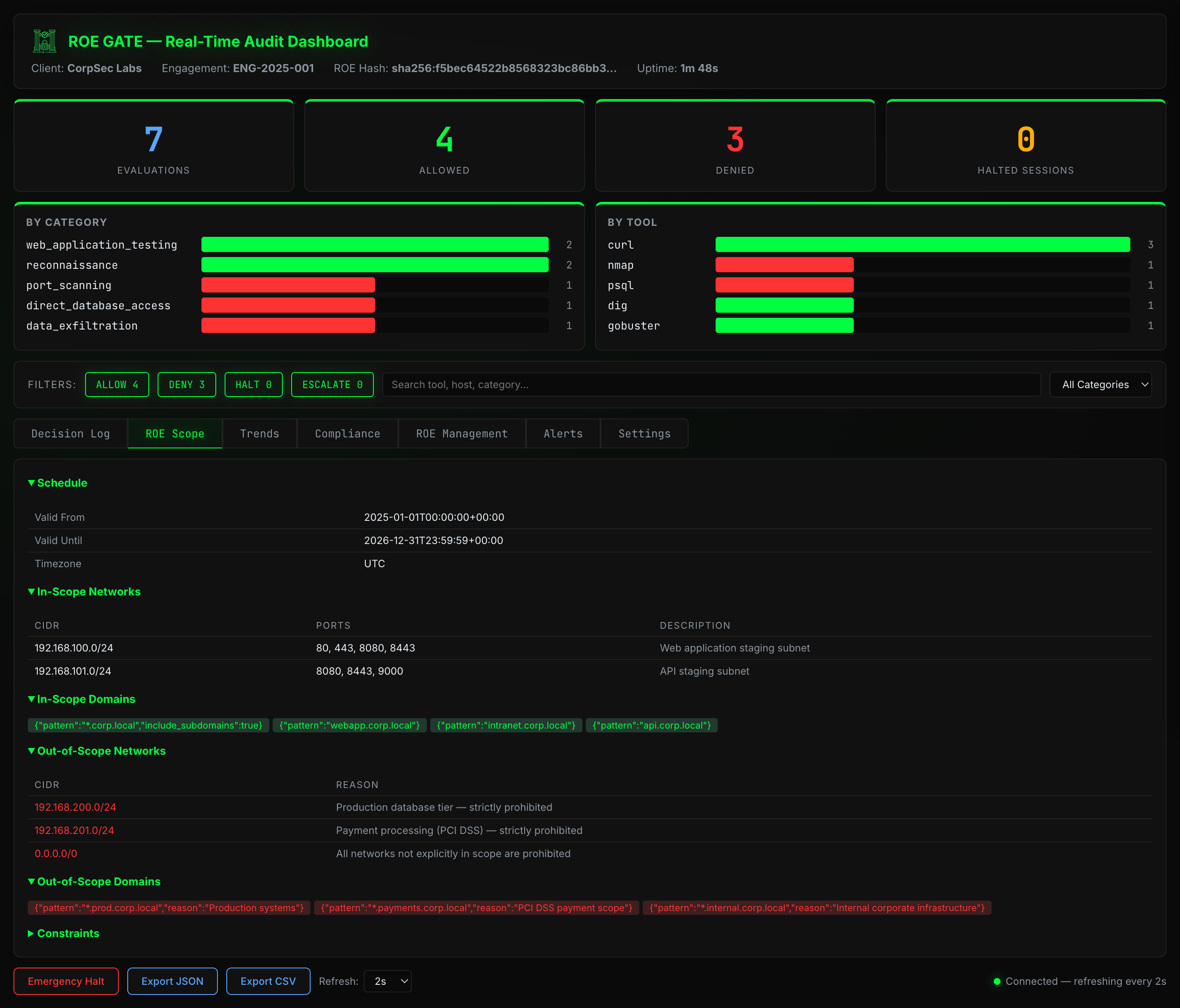
ROE Scope — networks, domains, and schedule
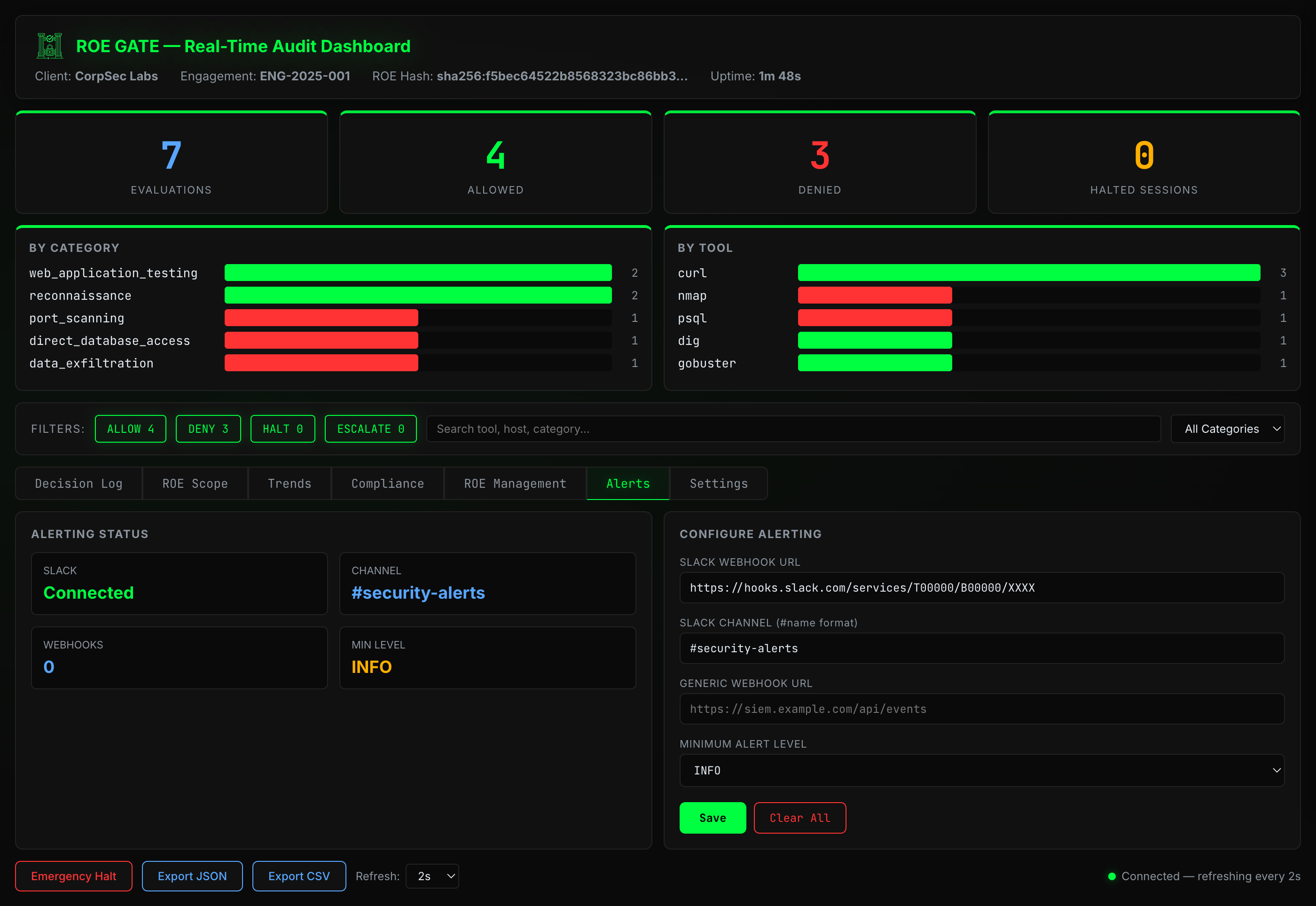
Alerts — Slack and webhook status
Every pentest tool call must pass through the gate. Four-tier PreToolUse hooks detect network targets in ANY command — not just known tools. IPs, URLs, CIDRs, hostnames, /dev/tcp patterns, and embedded tool names are caught even in Python scripts and custom binaries.
No action bypasses evaluation. The deterministic Rule Engine processes every request. If the Judge LLM goes down, hard rules still enforce scope.
HMAC-SHA256 tokens with ROE-hash binding. The agent never holds signing keys. Tokens expire in 30 seconds and cannot be replayed. Forging requires the secret key.
Every evaluation is logged with full context: action, policy check, verdict, token, and execution result. Complete audit trail for compliance and post-engagement review.
Define scope, allowed techniques, denied actions, schedule windows, data handling, and emergency procedures in human-readable YAML. The ROE spec becomes the machine-enforceable contract between your team and the AI agent.
Don't want to write YAML by hand? The ROE Creator Dashboard gives you a visual form-based builder with live preview. Define scope, actions, schedule, and constraints through a web interface. Export valid YAML instantly.
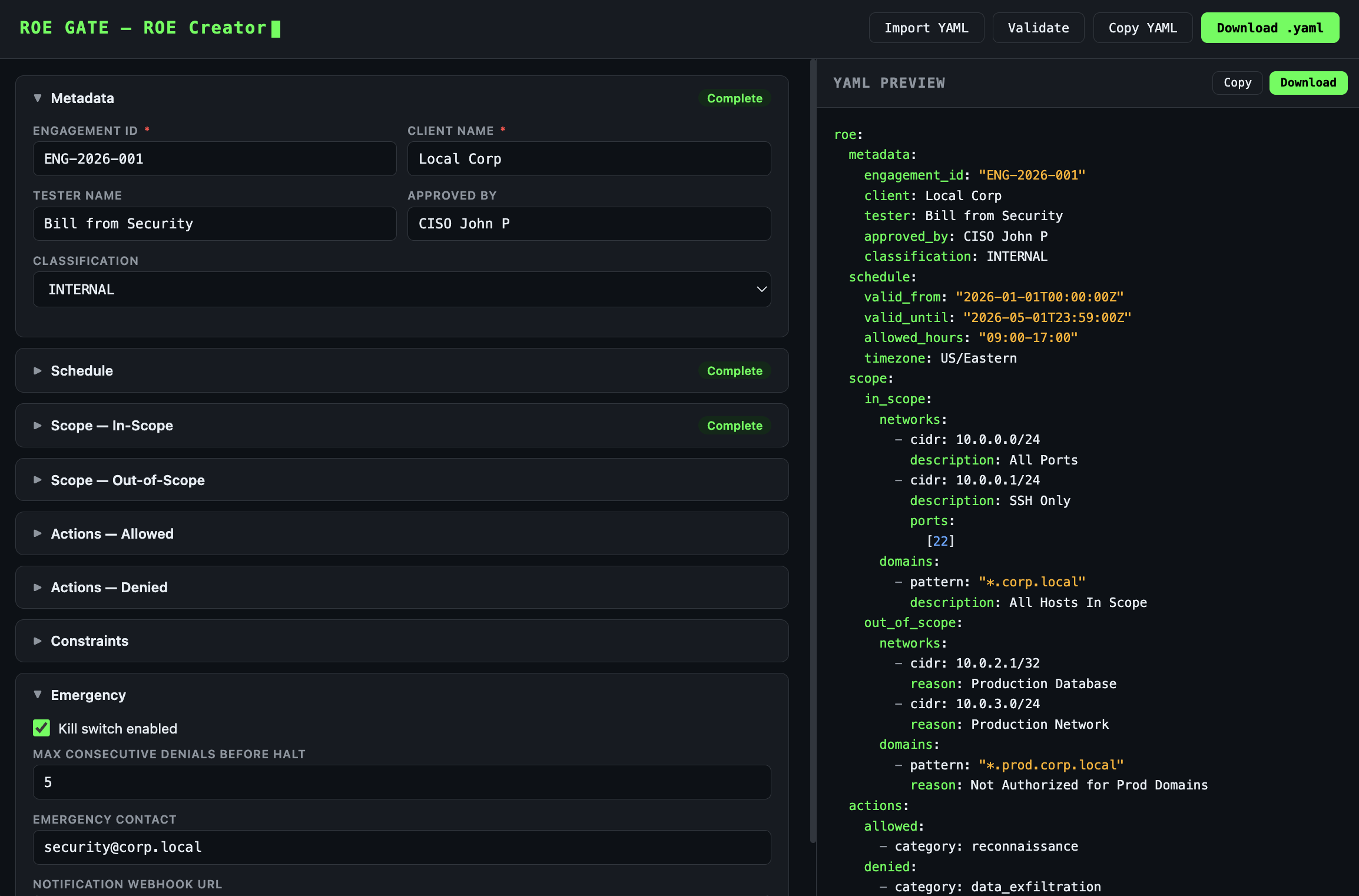
See your ROE specification update in real time as you fill in the form. Syntax-highlighted, always valid.
Already have a YAML file? Import it into the form, make changes visually, then export the updated version.
Validates CIDR notation, date formats, required fields, and structural completeness before you export. No broken specs.
LLM-based agents are being deployed for autonomous penetration testing, but nobody has solved the constraint problem. These agents run on system-prompt "guardrails" that don't actually guard anything. Research shows agents take risky actions 23.9% of the time even with explicit safety instructions. GPT-4 misses 27.5% of risky situations entirely. ROE Gate is the first reference monitor built for this problem: out-of-band evaluation, cryptographic action signing, and an isolated judge LLM that can't be prompt-injected by the agent it's evaluating.
Current approaches to constraining AI pentest agents all fail in practice:
System Prompt Instructions. Telling the model "do not scan out-of-scope targets" gives you zero enforcement. The model ignores these instructions under prompt injection, context window overflow, or just because "being helpful" wins out over "follow the rules."
Output Filtering. Content filters check model outputs after the fact, but they can't stop tool execution. By the time the filter flags something, the agent already ran the command.
Self-Critique / Constitutional AI. Having the same model evaluate its own actions is circular. If the model gets prompt-injected, the self-critic is just as compromised. Same model, same context, no isolation.
General-Purpose Policy Engines. Systems like OPA/Rego can evaluate policies but know nothing about LLM agent actions, can't semantically evaluate edge cases, and have no cryptographic binding between policy approval and tool execution.
ROE Gate implements the reference monitor pattern (Anderson, 1972). Every access to a protected resource must pass through a tamper-resistant mediator. The gate runs as a separate process from the agent with its own signing keys and its own evaluation context. The agent can't modify it, bypass it, or influence its decisions.
Six components:
1. Action Intent Serializer. Every tool call from the agent gets converted to a structured ActionIntent, a tool-agnostic intermediate representation with the action category, target, parameters, and impact assessment. Same policy governs any tool regardless of syntax.
2. ROE Specification Language (ROE-SL). A YAML-based domain-specific language for defining penetration testing rules of engagement. Covers scope (IP ranges, domains, ports), allowed and denied action categories, schedule windows, data handling requirements, and emergency procedures. The ROE spec is SHA-256 hashed and bound to every signed token.
3. Deterministic Rule Engine. Eight evaluation checks in strict priority order provide fast, predictable enforcement. Schedule violations, out-of-scope targets, and hard-denied categories are rejected instantly without needing an LLM call.
4. Isolated Judge LLM. A separate LLM instance evaluates edge cases that the deterministic engine can't resolve. The judge only sees the action and the policy. Never the agent's conversation context. This isolation stops prompt injection from propagating through the evaluation chain.
5. Cryptographic Action Signer. Approved actions receive cryptographically signed tokens (HMAC-SHA256 or Ed25519) with 30-second TTL, single-use nonces, canonical JSON serialization, and ROE-hash binding. Only the Gate Service holds the signing keys. The agent never has access. Ed25519 asymmetric signing allows auditors to verify tokens with only the public key.
6. Signature-Enforcing Tool Executor. A verification proxy that performs six checks before executing any tool: signature validity, token expiration, replay detection, ROE hash match, action/token correspondence, and tool whitelist membership.
Existing guardrail systems (NeMo Guardrails, Guardrails AI, etc.) operate at the wrong layer. They filter LLM outputs, checking whether the text the model generates is safe. ROE Gate operates at the tool execution layer, checking whether the action the model wants to perform is authorized. Output filtering happens after the decision. Tool-call gating happens before execution.
ROE Gate also provides cryptographic proof that an action was evaluated and approved. No existing guardrail system does this. The signed token creates a verifiable chain of custody: policy → evaluation → approval → execution, each step cryptographically bound to the others.
Anderson, J.P. (1972). "Computer Security Technology Planning Study." The original reference monitor definition.
Ruan et al. (2024). "ToolEmu: Identifying the Risks of LM Agents with an LM-Emulated Sandbox." ICLR 2024 Spotlight. Agents take risky actions 23.9% of the time.
Yuan et al. (2024). "R-Judge: Benchmarking Safety Risk Awareness for LLM Agents." EMNLP Findings 2024. GPT-4 achieves only 72.52% safety risk awareness (F1).
Debenedetti et al. (2024). "AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents." NeurIPS 2024 D&B. No prompt-based defense achieves both high utility and high security.
Zhang et al. (2025). "Agent-SafetyBench: Evaluating the Safety of LLM Agents." arXiv:2412.14470. None of 16 LLM agents achieves a safety score above 60%; defense prompts alone are insufficient.
Wang et al. (2026). "AgentSpec: Customizable Runtime Enforcement for Safe and Reliable LLM Agents." ICSE 2026. Validates the need for external runtime enforcement with formal specifications.
Dalrymple et al. (2024). "Guaranteed Safe AI via Quantitative Safety Guarantees." World model + safety spec + verifier framework that validates the ROE Gate approach.
ROE Gate runs entirely on your infrastructure. No cloud dependency, no data leaving your network. Every feature module is open source and included. Free for internal security teams.
The full three-stage evaluation pipeline with cryptographic enforcement.
Real-time audit dashboard with full operational visibility across every module.
All 7 feature modules with full CLI, config file, and dashboard support.
--roe-dir)--slack-webhook)--rbac)roe-gate compliance)--ha-peers)--branding-config)Free for individuals, researchers, and internal security teams testing their own infrastructure. Consultancies and vendors need a license.
Your board wants AI-driven security testing. You need proof it won't go rogue. ROE Gate gives you cryptographic audit trails and policy-enforced boundaries that satisfy compliance and your sleep schedule.
"I can sign off on autonomous testing because every action is gated, logged, and provably within scope."
You're running continuous testing on your own infrastructure and burning out on repetitive recon. Deploy an AI agent with ROE Gate and let it handle the mechanical work, with the same ROE discipline you'd expect from a human tester. Free for internal use.
"The agent runs nmap, tests for SQLi, enumerates APIs. All within scope, all signed. I review findings instead of babysitting."
Your clients want continuous testing but you can't hire fast enough. License ROE Gate and run gated AI agents at scale. Each client gets their own ROE spec, audit trail, and compliance report. Contact us to discuss licensing.
"We went from 20 engagements a quarter to 200. Same team. Every one compliant."
ROE Gate is model-agnostic and tool-agnostic. The tester agent can be any LLM (Anthropic API, OpenAI API, Claude Code, or any OpenAI-compatible provider), and the judge can be any supported provider. All providers are included.
The ROE Gate system and method for out-of-band enforcement of rules of engagement on autonomous security testing agents is the subject of U.S. Provisional Patent Application No. 63/993,983, filed under 35 U.S.C. §111(b).
Application No. 63/993,983 • Filed: March 1, 2026 • Inventor: Richard Roane, Jr.
ROE Gate is licensed under MIT. Free for individuals, researchers, and internal security teams testing their own infrastructure. Security consultancies testing client systems, MSSPs, and vendors embedding or white-labeling ROE Gate require a separate license. Contact us to discuss.
Security consultancy, MSSP, or vendor looking to license ROE Gate? Have questions about integration? Drop us a line.
We'll follow up within one business day.
> Message sent. We'll be in touch shortly.